
And how does it differ from data catalogs or data discovery tools?

The term data glossary is increasingly being used, yet it’s not always clear what it refers to and what is the purpose of building one. Worse, this term is often used interchangeably with the words “ data dictionary” and “ data catalog”. Although these concepts belong to the same family, all related to data and metadata management, they differ in important ways. Understanding their differences and how they interact is a key step in successful data management. The aim of this article is thus to explain what a data glossary is, why it’s important, and how it’s related to the two aforementioned concepts.
What is a data glossary?
A data glossary, also referred to as “business glossary” is nothing more than a list of business terms attached to their definitions. The sole purpose of a data glossary is to define business terms for an organization, in order to bring harmony around the concepts used in a system.
The concept of a data glossary is dead simple but extremely important. A well-maintained business glossary ensures everyone within the same organization speaks the same language. It is basically a source of truth for all the business terms used in a business.

Why is a data glossary useful?
Maintaining a business glossary is a simple task: build a repository of the words you use when conducting business operations, and attach them to a definition. Ensure everyone in the organization can access this repository easily. Although a data glossary is easy to build and maintain, it can have a strong impact on your business performance. In fact, business glossaries allow you to:
If you don’t have a clear repository of business terms used in your system and their definitions, chances are you’re unable to measure your KPIs. More specifically, various people in your company come up with different results for a specific metric, and you’re rarely able to pinpoint who’s got the right number. Why does this kind of problem occur? Well, language is always subject to interpretation. How often do you find yourself persuaded of the meaning of a business term when a colleague is totally convinced that it means something else? Say, when analyzing customer churn, you’ve assumed “customers” were users that have been active on your app in the past week. Turns out the marketing team is using a slightly different definition, viewing customers as people that have purchased something through the app in the past month. After months of both teams using two different definitions, there ends up being huge inconsistencies in the analyses produced. Dashboards from different teams don’t agree, numbers are inconsistent. Worse, these irregularities are often uncovered during a presentation to clients or C-suite level people, because this kind of situation provides a bird’s eye view of the system. But once you uncover the issue, it’s too late. People have already been using different definitions for months, maybe years, and every single dashboard has probably been contaminated.
Long story short, a business glossary is no luxury. It’s the first step to just calculating your KPIs, a basic activity that every organization should have relatively sorted out. Also, successfully calculating your KPIs and understanding the drivers of your growth is the first step towards a successful data journey. Without it, you probably can’t lay the data analysis and data science steps that usually follow.
If employees in a company aren’t aligned around a common understanding of business terms, trust quickly vanishes, wasting all the analysis efforts. If an executive, or a client, is presented with two reports describing the same term without context on why they don’t agree, how will they react? Well, they will distrust both reports, the team that produced them, as well as the data owned by the company. What’s the aim of hiring a data team that spends its time building dashboards and reports if you can’t trust their work? Again, once these mistakes have reached the report level, it is extremely difficult to pinpoint where exactly they originate. Is the report wrong because it used the wrong definition for “customer churn”? Or because the metrics used to calculate customer church were themselves wrong due to misspecification and improper definitions? With a well-maintained data glossary, it becomes easy for a user to find what a specific term refers to. When a user fails to understand a report, he can just drill down to the definition in the data glossary system. This promotes productivity, efficiency, and enterprise data trust.
A well-maintained data glossary can be the foundation of a successful data governance initiative. Establishing clear standards for data terms and definitions improves the organization’s knowledge. This well-organized knowledge repository can help users define rules and maintain access policies using the data glossary terms. For example, this can be achieved by assigning a level of security to specific business terms, then define data governance policies based on these security levels. A data glossary can also include data quality rules, flagging data quality issues to data users. For this reason, a data glossary is a key deliverable in a data governance initiative.
In short, data glossaries belong to the kind of actions that are low effort & high impact. They’re well worth building, maintaining, and sharing.
Data glossary vs data dictionary: the difference
Although referring to fundamentally different things, the terms ‘data glossary’ and ‘data dictionary’ are often used interchangeably. That’s why I’d like to bring a bit of clarity on how they differ and how they can be related.
A data glossary is just a bunch of business terms and their definitions. We’ve covered this. On the flip side, a data dictionary seeks to enrich each database with metadata.
According to the DAMA Dictionary of Data Management, a data dictionary is:
“A place where business and/or technical terms and definitions are stored. Typically, data dictionaries are designed to store a limited set of metadata concentrating on the names and definitions relating to the physical data and related objects.”
It is a collection of information about data terms which can be database schemas, tables, or columns. In data dictionaries, a user will usually find information about:
Data type
Size
Default values
Constraints
Relationship to other data
The meaning/purpose of a given table or column
Whether the information is PII or not
If you’re not sure of the meaning of metadata, and why it’s key for your company to collect and exploit it, here’s an article that brings clarity on the matter.
Data dictionaries are usually used to provide consistency in data collection, enforce the use of data standards, and show the relationship between data assets.
Data dictionaries cater to technical users, such as data analysts and data scientists. Technical people consult the data dictionary to improve their understanding of the data, allowing them to manage, move, merge and analyze data efficiently. They’re also more system-specific.
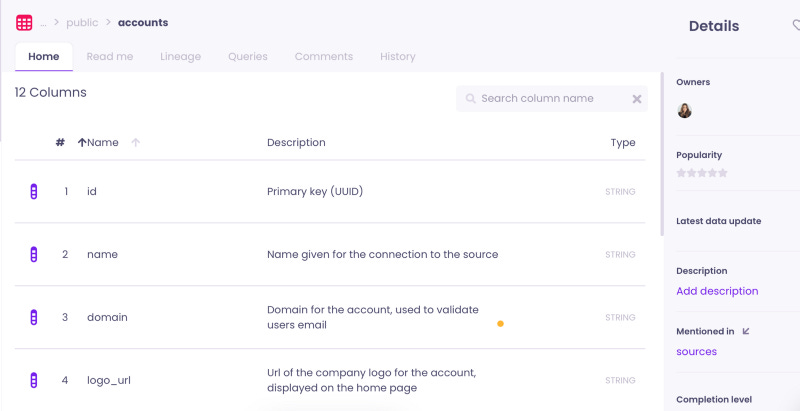
Data catalog: Tying the data glossary with the data dictionary to leverage your data seamlessly

We have a third term that’s alternatively mixed up with a data dictionary and data glossary: the data catalog. the data catalog is the glue tying the data dictionary and the data glossary together. It’s a metadata management solution offering the possibility to store both in a single repository. But why would you want to do so?
Although data dictionaries and business glossaries are different entities, they work as a great tandem that can ultimately produce a single source of truth about your data. Having information about both your data assets and business terms in the same repository opens a myriad of possibilities. For example, a data catalog allows various technical terms of the data dictionary to be tied with a single business concept in the business glossary. This helps conceptualizing technical elements using a business angle.

Gathering your data glossary and your data dictionary in the same place helps along two key dimensions:
Tying your data dictionary and data glossary together ensures data analytics and business strategy are fully aligned in your organization. In fact, the data catalog software maps business terms to specific tables and columns in a data dictionary to provide additional context around each database.
This mapping is key, as clear business definitions bring about limited value if they are not linked to the underlying data. When data dictionaries and business glossaries are linked, users can easily locate data associated with a business term without having to hunt for it with the BI team. Similarly, the technical documentation provided by the data dictionary greatly helps data people. However, if it isn’t linked to the data glossary containing business definitions, the data team has no idea about the context in which data sources are used, for which purpose, with which requirements, etc.
Data manipulation used to be exclusively reserved for data scientists and data analysts, it’s not the case anymore. Today, sales, marketing, and other operational departments are using data to fuel their daily operations. That’s why self-service analytics has become such a buzzword. Self-service analytics just refer to enabling non-technical users to access data for self-directed discovery, analysis, visualization, and hypothesis testing. When data assets are closely tied to the business concepts thanks to data catalog tools, this makes it much easier for marketers and other business people to find the data they need.
Data catalogs allow open access to data are open to all users, regardless of their level of technicality. This not only saves time to data users who immediately get the context they need, but also bridges the gap between a database and its related business context.
The key functionalities of a data catalog
An enterprise data catalog is a metadata management software, used for data governance and data discovery purposes. Looking at each use case:
Data governance: As we have seen above, an enterprise data catalog links each data asset to its business context, making it easier for data users to understand the requirements around an asset. For example, for a given data asset, you understand both what the database contains and requirements around it: whether it contains PII information, how much time should pass before it is deleted, whether access to it should be open to the whole company, or restricted to a few roles only, etc
Data discovery: With a data catalog, each data asset is enriched with context about what it contains, who imported it into the company, which dashboard and KPI it is related to, and any other information that can help data scientists locate it. In short, a data catalog makes your data discoverable by finally bringing clarity to your systems**.**
Modern data catalogs are completely automated tools, that use machine learning to enrich the documentation of your data warehouse. This way, they offer great support to data stewards, who don’t have to document datasets manually thanks to these tools.
If you’re looking for an enterprise data catalog, we’ve listed all the tools available on the market here (SaaS, open-source, etc..).
About us
We write about all the processes involved when leveraging data assets: from the modern data stack to data teams composition, to data governance. Our blog covers the technical and the less technical aspects of creating tangible value from data. If you’re a data leader and would like to discuss these topics in more depth, join the community we’ve created for that!
At Castor, we are building a data documentation tool for the Notion, Figma, Slack generation. Or data-wise for the Fivetran, Looker, Snowflake, DBT aficionados. We designed our catalog software to be easy to use, delightful and friendly.
Want to check it out? Reach out to us and we will show you a demo.
Originally published at https://www.castordoc.com.